kbrecordzz
Home - About - Contact - Overview - Resources
The internet is cool, a lot of computers around the whole world are connected to each other in all possible directions and angles, and because of that you can do almost anything. There's no single definitive way for how your computer connects to my web server in Stockholm, but when you visit https://notacarclub.kbrecordzz.com it indeed happens, there are actually many different paths the data can take between your computer and my server, it can change at any time, even in the middle of a connection, and I never understood how it works. The standard explanation for how the internet works, if you're not looking in thick technical books that require you to already know the answer before you can read it, is that "you enter the domain name "google.com" into your browser, then the browser asks a "DNS server" to convert that domain name to an IP address, which is a type of address that your computer understands" and then everything works. But it still doesn't explain why the data takes certain paths, and what makes it do it, which is weird because that's what the internet is: Data taking different paths between computers all around the world. There are billions of computers and they obviously need to keep track of where the other billions of computers are. How is it possible?
About the "standard explanation" I just talked about: IP addresses (94.254.0.153) aren't more understandable by a computer than domain names (notacarclub.kbrecordzz.com), but it just happens to be the language the routers on the internet have chosen to speak. Both are code words for a computer/server on the internet, and neither say anything about its geographical location or about how the computer/server is connected to different cables and wires. In another timeline, we could have been calling websites by their IP addresses, or routers could have worked directly with the domain names, but because of the internet's history and how we've handled its growing complexity (at first, all the world's domain names were listed in a single "HOSTS.TXT" file that everyone had on their computer!), we now live in a world where we have to do an extra step where the domain name we enter needs to be converted to an IP address, so the routers over all of the internet can work with it. This is the "domain name system" (DNS) and you can read about in a million places, just search for "how does the internet work" and read whatever that pops up (except this text).
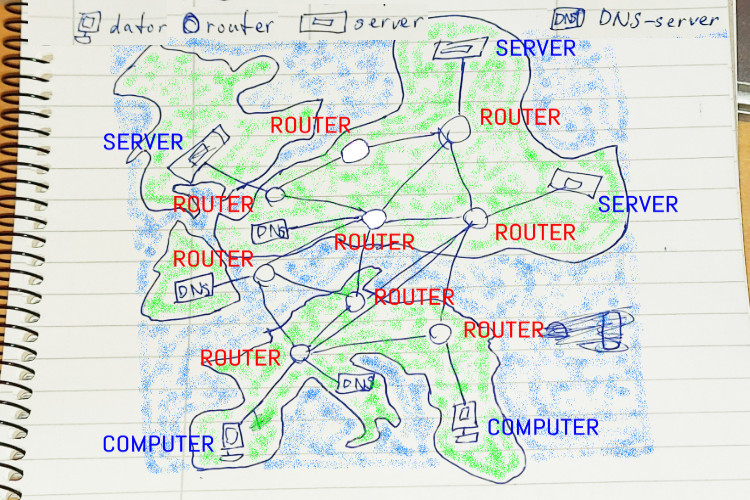
The computer doesn't understand IP addresses, but the routers on the internet do. They connect everything on the internet and make sure all data gets sent to the right place. As you can see on the cover image above, routers are connected to multiple other routers, and whenever they get data sent to them from another router, they choose through which cable to send the data further towards another router, in order to make the data get closer to its goal destination. They do this by looking at the IP address, and comparing it to a list ("routing table") that has a bunch of IP addresses and a corresponding output/cable called "next hop" or something similar, which is "the next hop to do in order to get closer to the goal (I'm using the word "cable" here to make it easier to understand the physical reality. The router doesn't see it as cables, and it doesn't have to be cables either, it can be wireless, etc):
IP address | Next hop 94.254.0.153 | eth0 94.254.0.154 | eth0 62.63.232.99 | eth1(Extremely simplified example of a routing table, search the web for more real examples. "Next hop" is which cable/interface to go through in order to travel one step closer to the goal ("IP address"))
But each single router having a list of all computers' IP addresses would be too much, so instead they have a list of many NETWORKS. A network consists of many computers and therefore many IP addresses, it can for example own all IP addresses starting with "94.254.0.xxx". And every router doesn't necessarily store all networks, so if a router doesn't know about the particular network, it can send the data to another router that is close, and see if that router can handle it instead. The first couple of routers only need to know about the approximate situation, to help send the data to a router closer to the goal, that knows more. In the end, we hopefully reach a router that owns the network we're looking for (if you're visiting https://kbrecordzz.com, it's my internet service provider Bahnhof), and that knows about all of its IP addresses, and it can send us to the correct server directly. That's it. As you see, no router knows everything, but together they do, and they help each other to make it all work.
So, DNS lookup to convert domain name to IP address, and then send the data - together with the IP address - to routers across the world and they'll collaborate to let you reach the goal. Then the data will be sent back and forth between you and the website you're visiting (and, the DNS lookup probably also uses routing to reach the DNS servers, which is a bit ironic). It may feel like you're only downloading a webpage when you visit one, and not uploading anything, but it all starts with you uploading an "HTTP GET" request to a server, which then sends you the requested data (a webpage) back. So there's always uploading and downloading back and forth.
That's the explanation I've always missed on the internet. Everybody talks about DNS but no one talks about routing, when in fact both are crucial! The good thing is that I had to go through copious amounts of information to learn this, and now I know enough about the internet to start exploiting it! My goal with all of this is still to make a game for the web (because mobile web browsers are the new GameBoy Advance) that starts fast, runs fast and works without problems for a long time (50+ years?). Last year (yes, I'm linking to the same post again) I tried to achieve this by working around the flaws of web browsers and programming languages, in order to create websites that remain stable through times in an internet that constantly changes and breaks. Web browsers change over time and I tried to withstand this by writing timeless HTML and Javascript code that works in both old, current, and hopefully future browser versions. A website is just a file(s) that you download, and that file can be manipulated to be exactly what you want. But you can also manipulate the technology you send the data over: Place your server closer to the users, find shorter paths to the users, have reserve infrastructure in case your stuff breaks, and so on. It's harder to manipulate the actual physical internet, because you probably don't own multiple oceanic underwater fiber cables, because you aren't Telia, but that also makes it more fun!
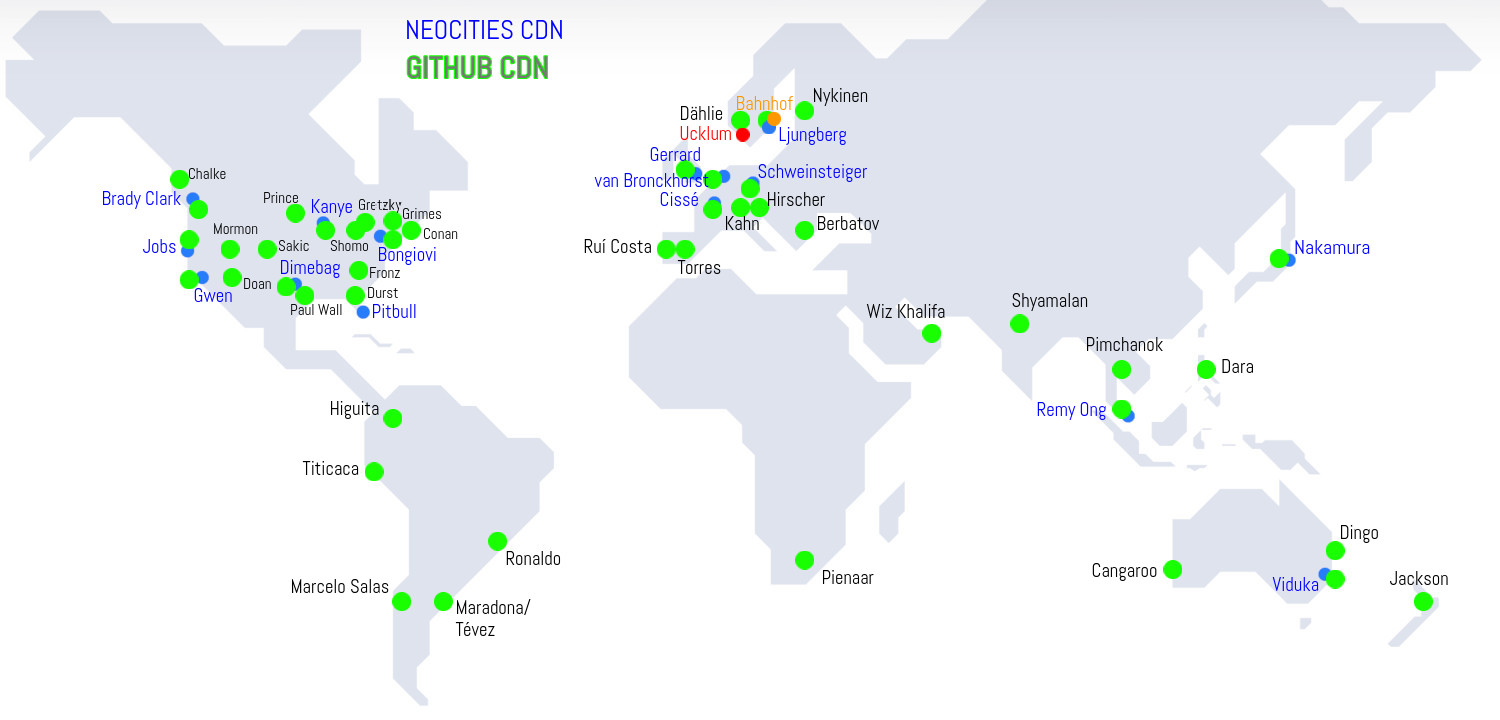
Introducing G.I.R.L. ("Galactic International Raceway for Live entertainment"), a system I've designed for getting 100% uptime and fast access in all parts of the world for my game. I use both DNS and routing for this. I take advantage of content delivery networks ("CDN") and how they manipulate routers' routing rules based on geography, to serve you content (my game) from a server close to you. A typical CDN owns multiple servers around the world and can serve you websites/content from all of them. If you're in Sweden you'll be served by the server in Stockholm, and if you're somewhere in southern Africa, it may serve you content from the server in Johannesburg. All this is done because the routers, based on where in the world they're located, have different info about the CDNs IP addresses in their routing tables. An IP address doesn't have to lead to one specific web server or location, because with "BGP Anycast" (read or listen more about how Neocities' Kyle Drake got his CDN up and running with BGP Anycast), routing tables can be manipulated to let IP addresses mean different things in different geographical locations, and this will let users start my game / download my site faster because the internet connection won't go across the whole globe. But here's the twist: I use TWO content delivery networks. Both Neocities and Github Pages. For 100% uptime I need to spread both physically, geographically and organizationally, in case organizations do something bad and break my CDN, and that's why I'll take advantage of DNS and how modern web browsers hopefully handles multiple IP addresses listed in DNS records. What I do is that I let my domain name "kbz.se" lead to two different CDNs (two different IP addresses) - Neocities and Github Pages - in my DNS records, which makes it so that if one of the CDNs wouldn't work, for example if it has an outage and is completely unavailable, web browsers will try the other CDN after around 30 seconds. That's just how DNS and browsers seem to work. Here I put all my faith into web browsers and hope they won't change this behavior in the future.

So you'll never reach a dead page with a "server error" message, because the failed CDN will hopefully be fixed before the other CDN also goes down unexpectedly, or I'll manage to find and setup a new CDN service in the same time. So you will always reach at least one of the CDNs. This will also reduce the pressure on the servers, because all visitors won't visit the same servers or even the same system. These methods combined mean that when you visit my game, you'll be redirected to either my site on Neocities or on Github Pages, which in turn will redirect you to one of their many servers. And all the servers will have the exact same content (my game) on them, so you won't notice that they're different servers. So, 100% uptime (because of 2 CDNs and DNS settings), and fast access in all parts of the world (because of CDNs manipulation of routing rules). Which lets my game start fast, run fast and work without problems for a long time, even if the internet "breaks", which it will inevitably do.
G.I.R.L. is still experimental, and only used for https://kbz.se as of now. For various reasons I couldn't use "notacarclub.kbrecordzz.com" for this kind of system, so the plan now is to let "kbz.se" become a platform for both my game and future projects. So if everything goes as planned, kbz.se will be a website that is BOTH on Neocities and on Github Pages, as two identical copies, and whenever you visit it you'll download the webpage from one of these. Neocities has 15 CDN servers and Github Pages seems to have around 45, so kbz.se is in total on ~60 servers around the world. And of course I've named them after semi-famous football (soccer) players from the mid-2000s (mostly). This map is also the start of kbrecordzz coming closer to becoming a global, premier, high-end, all-media entertainment production conglomerate: